Conversation with a Machine. Part 1
Writing code is only the first step in the interaction between a programmer and a machine. What happens next sits somewhere between magic and a very sophisticated act of translation.
In this post I take a look at high-level programming languages and their relationship with natural languages. It’s a topic that has fascinated me for years, largely because of its complexity. How does code — built from symbols taken from written human language — become something a computer can process? What role does the programming language itself play in that process? And where exactly is the boundary of understanding between a programmer and a machine?
These questions are only a tiny slice of a much larger universe of problems that we rarely think about while writing code. To explore them properly, we need to organize a few basics first.
Two fingers
You can describe the fundamental components of any language using the fingers of one hand. In fact, two fingers are enough. Every language can be defined in terms of its:
- vocabulary
- grammar
Vocabulary is simply the set of language units that carry meaning for its users — let’s call them words. Grammar is the set of rules that tells us how those words can be combined into larger statements.
Every language user intuitively understands the vocabulary they use. We learn it from an early age — first as sounds, then syllables, then words. Over time we learn how to combine those words into longer expressions that other speakers of the same language can understand. The rules governing how these smaller pieces combine into meaningful statements are what grammar describes.
By the time we learn programming, we’re already fairly competent users of at least one natural language. That turns out to be helpful, because most high-level programming languages (anything above assembly) share a surprising number of structural similarities with natural languages.
Building blocks
Programming languages, just like natural ones, can be described in terms of vocabulary and grammar.
On the grammar side, the key element is the set of rules that define how symbols in a language can be combined into valid expressions. In computer science we call this the syntax of a language. Break those rules and — to put it mildly — your program crashes. Anyone who’s written code probably has an impressive personal archive of syntax errors.
On the vocabulary side, programming languages include data types, operators, and keywords. Data types define — well — the types of data a program works with (for example booleans or strings), and they determine which operations can be performed on that data.
Programming languages often allow expressions that are syntactically valid but semantically wrong. For example, in Python:
x = "Galaxy" + 42
The Python interpreter will throw a TypeError here because we’re trying to add two incompatible types. Natural languages allow something similar. You can construct a sentence that is grammatically correct but semantically nonsensical — like “colorless green ideas sleep furiously”. You can say it, sure. But it doesn’t guarantee anyone will understand you — at least not while sober.
Operators are special symbols used to perform operations on data. There are arithmetic, logical, bitwise operators, and so on. In Python, for example, * represents multiplication and == compares values.
Keywords are particularly interesting in this context. These are words that have a special meaning within a programming language and cannot be reused as identifiers like variable or function names. They are effectively reserved for the compiler or interpreter. Because their meaning is fixed, they play a crucial role in the language’s semantics. In most programming languages, for example, for indicates a loop, if represents a condition, and return ends a function and sends a value back to where it was called.
Keywords resemble a small, constrained subset of English vocabulary, which makes sense because English forms the foundation of most mainstream programming languages. Just take a look at the keyword lists for Python or Java. Add in the functions and structures from standard libraries and you end up with a surprisingly large collection of words — enough that many native speakers wouldn’t feel outmatched.
And code still leaves plenty of room for creativity. Programmers invent their own names for variables and functions, and they write comments explaining what’s going on. Sometimes, when you look at a piece of code, it almost reads like math notes written in natural language.
Take this simple Python function:
def add(a, b):
"""
The function adds two numbers.
Arguments:
a: First number.
b: Second number.
Returns:
The sum of a and b.
"""
return a + b
result = add(5, 3)
print(result) # Expected result: 8
Even someone who doesn’t program can probably get the gist of what’s happening here. Comments — the text between """ and after # — make it even clearer.
Comments reveal the human side of code. They are almost a separate language, used by programmers to communicate with other programmers.
The CPU, however, couldn’t care less about them. It ignores comments entirely, just like it ignores other human-friendly aspects of code. It doesn’t care whether your function is named add, xyz, or ItsBritneyBeach. All of that gets lost in translation during compilation or interpretation.
Compilation time
Compilation and interpretation both happen outside the programmer’s control. They are complex, multi-stage processes, but they are essential for bridging the gap between programmer and machine. The early stages operate directly on the language itself. These include:
-
Lexical analysis (lexing) — the code written by the programmer is split into tokens, the smallest meaningful units such as keywords, identifiers, and operators
-
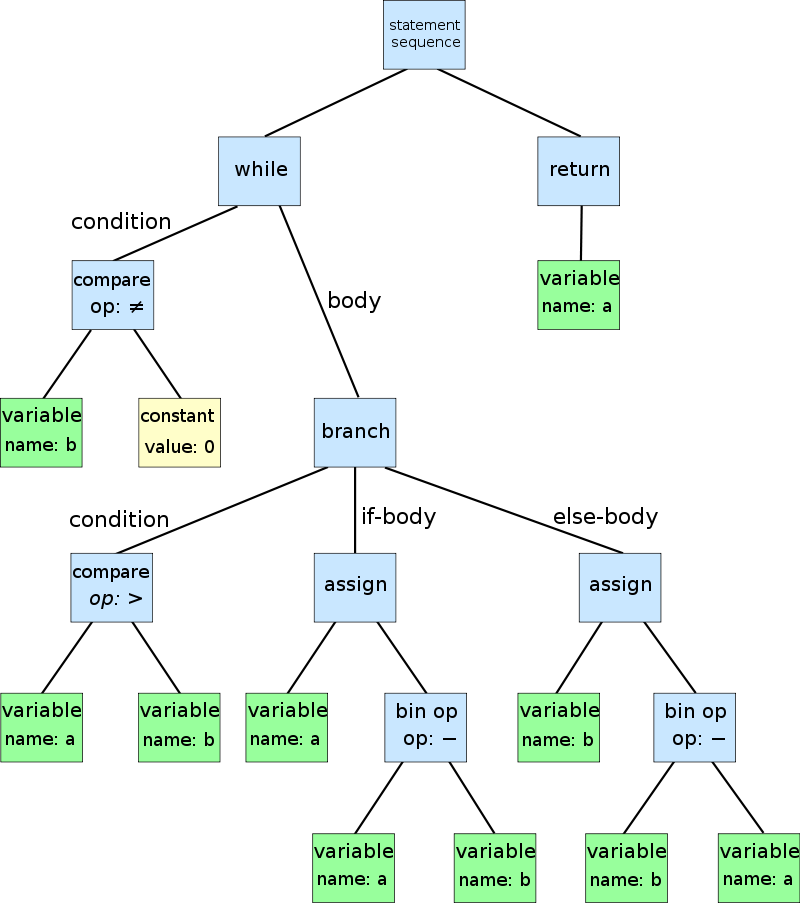
Syntax analysis (parsing) — the system checks whether the sequence of tokens follows the syntactic rules of the language. The result is an abstract syntax tree (AST), often visualized literally as a tree structure — for example like this
-
Semantic analysis — the code is checked for meaning. Syntactically correct code can still be logically wrong. At this stage the compiler verifies things like type compatibility, whether variables are declared before use, or whether a function receives the correct number of arguments.
{kind=link}
This is a wildly simplified overview of the first steps in processing source code during compilation or interpretation. I’ll skip the later stages for now and jump straight to the results.
Compilation produces an executable file or bytecode for a language-specific virtual machine. Only after that can the program actually run. Interpretation, on the other hand, executes code on the fly, so all the steps described above happen at runtime. That’s why compiled languages are generally faster — although many factors influence performance.
These days, however, many languages blur the line between compiled and interpreted. Java compiles to bytecode, which is then interpreted by the Java Virtual Machine (JVM). Inside the JVM, a JIT compiler identifies frequently executed fragments (so-called hotspots) and compiles them into machine code on the fly.
JavaScript is theoretically interpreted, but engines like V8 (used by Chrome) also use JIT compilation to translate source code into native machine code during execution.
Which, honestly, feels like magic.
Talking to a painting
Humans have a natural tendency to anthropomorphize the systems around us. We say things like computers “understand” binary language made of zeros and ones. That they “speak” it. That we “communicate” with them by writing code.
Bullshit.
The whole recap of compilation and interpretation was meant to highlight one thing: writing code in a high-level language is not actually communicating with the machine. It’s not the machine’s language, because the machine doesn’t understand it.
Computers — or more precisely processors — simply execute instructions defined by their architecture. They don’t speak or understand anything. They just work. Relentlessly. Billions or even trillions of operations per second. Modern processors are almost unimaginably fast.
Programming languages are a convenient abstraction layer for humans. They allow us to write code that humans can read and reason about. During compilation or interpretation (sometimes both), that code is translated into another representation that the CPU can execute.
This translation step — from human-readable code to something a processor can run — is an impressive piece of engineering. All the real magic happens inside compilers and interpreters, which handle this messy translation process for us.
When we give a processor instructions written in its “language”, we also implicitly accept that the response will come in a completely different form. We don’t expect a reply in the same language. Instead we expect a result — some observable behavior in software.
Half-jokingly: writing a program is a bit like speaking English to someone so that a translator (the compiler) can convert it into the language of bees and return an answer in the form of, say, the Candy Crush mobile app.
That’s why calling programming languages “languages” is slightly misleading. They share structural properties with natural languages — vocabulary and grammar — but from a communication perspective they work very differently.
Let’s summarize the key differences:
- programming languages require an additional translation layer (compilation, interpretation, or both) before the receiver can process them
- communication is one-way: the programmer sends instructions and the processor executes them — never the other way around
- the result of “speaking” to the machine is not language but action: a calculation, an application, a graphic, or some other behavior
In that sense, programming languages resemble systems like semaphores or road signs more than natural languages. They encode information using symbols and rules. Road signs convey traffic information to drivers. C code conveys instructions to a compiler about what operations should become native machine code.
In both cases the flow of communication is one-directional: from the sender who defines the rules to the CPU that executes them. The “response” is simply software that works better — or worse.
 Photo: Matt Bango, CC license, source
Photo: Matt Bango, CC license, source
Programming languages undeniably intersect with natural languages in many interesting ways — but that’s a topic for the next post.