Rozmowa z maszyną. Część 1
Pisanie kodu to zaledwie wstęp do komunikacji między programistą a maszyną. Dalej dzieją się rzeczy z pogranicza magii i sztuki przekładu wyniesionej na najwyższy poziom.
W tym poście przyglądam się językom programowania wysokiego poziomu w kontekście ich relacji z językami naturalnymi. Jest to zagadnienie, które mnie fascynuje od lat i którego złożoność mnie zachwyca: w jaki sposób kod, zbudowany z symboli używanych w pisanej odmianie języka naturalnego, staje się czytelny dla komputera? W jakim stopniu język programowania uczestniczy w tym procesie? Gdzie przebiega granica porozumienia programisty z maszyną?
Te pytania to tylko mała część całego uniwersum problemów, nad którymi raczej się nie zastanawiamy podczas pisania kodu. Żeby wejść w nie na pełnej, zacznę od uporządkowania kilku tematów.
Dwa palce
Podstawowe elementy każdego języka można wyliczyć na palcach jednej dłoni. Właściwie wystarczą dwa, bo język można zdefiniować w kategoriach jego:
- słownika
- gramatyki
Słownik to w skrócie zbiór jednostek językowych niosących znaczenie dla użytkowników danego języka - nazwijmy te jednostki słowami. Gramatyka to reguły łączenia słów w większe wypowiedzi.
Każdy użytkownik języka intuicyjnie rozumie, czym jest używane przez niego słownictwo i jakie znaczenia mają poszczególne słowa. Uczymy się ich od małego, jako pojedynczych głosek, sylab, wyrazów. Z wiekiem dowiadujemy się, jak składać poznane słowa w większe wypowiedzi, aby być zrozumiałym dla innych ludzi mówiących tym samym językiem. Za reguły łączenia tych mniejszych części w wypowiedzi odpowiada właśnie gramatyka.
Programowania uczymy się na etapie życia, na którym jesteśmy już całkiem sprawnymi użytkownikami co najmniej jedno języka. To dobra wiadomość, bo właściwie wszystkie języki programowania wysokiego poziomu (powyżej asemblera) mają wiele cech wspólnych z językami naturalnymi.
Części składowe
Języki programowania, tak jak naturalne, można opisać kategoriami ich słownika i gramatyki.
W gramatyce najważniejsze są reguły, które określają, w jaki sposób łączyć symbole występujące w języku, aby tworzyć poprawne wyrażenia. W terminologii informatycznej zbiór tych reguł nazywa się składnią języka. Złamanie ich sprawia, że - mówiąc oględnie - programy się wywalają. Niech pierwszy rzuci kamieniem, kto nie ma na swoim koncie pokaźnej kolekcji syntax errors.
W zakresie słownictwa mamy w językach programowania typy danych, operatory i słowa kluczowe. Typy danych określają - no cóż - typy danych, których używa program (np. booleany, stringi) i które determinują jakie operacje można na nich wykonywać. W językach programowania gramatyka często pozwala konstrukcje gramatycznie poprawne, ale semantycznie błędne. Np. w Pythonie:
x = "Galaxy" + 42
Interpreter Pythona zwróci nam w tym przypadku TypeError, bo próbujemy wykonać operację dodawania rozbieżnych typach danych. W języku naturalnym również możemy stworzyć wyrażenie gramatycznie poprawne, ale semantycznie kalekie, jak na przykład “colorless green ideas sleep furiously”. Możemy tak oczywiście powiedzieć do naszego rozmówcy, ale nie gwarantuje to porozumienia - przynajniej na trzeźwo.
Operatory to specjalne symbole służące do wykonywania różnych operacji na danych. Występują operatory arytmetyczne, logiczne, bitowe, itp. W Pythonie to na przykład * używane jako symbol mnożenia albo == jako porównanie wartości.
Słowa kluczowe są w kontekście tego posta bardzo ciekawe. To wyrażenia, które mają specjalne znaczenie w danym języku programowania i nie mogą być używane w kodzie jako inne identyfikatory (np. nazwy zmiennych czy funkcji). Są one niejako zarezerwowane do użytku przez kompilator lub interpreter. Pełnią niezwykle ważną rolę w semantyce danego języka, bo mają ustabilizowane znaczenia. Na przykład w większości języków programowania słowo “for” oznacza pętlę, “if” warunek, a “return” instrukcję, która kończy wykonywanie funkcji i zwraca wartość do miejsca, z którego została ona wywołana.
Słowa kluczowe przypominają nieco ograniczony słownik języka angielskiego, bo ten właśnie język jest podstawą dla większości mainstreamowych języków wysokiego poziomu. Na dowód polecam przejrzeć listę keywords dla Pythona czy Javy. Jeśli do zestawu słów kluczowych dodamy elementy, które pochodzą z bibliotek standardowych danego języka, to powstanie nam już całkiem pokaźna kolekcja wyrażeń, której nie powstydziłby się niejeden native speaker. Ba, w kodzie jest jeszcze miejsce na swobodną twórczość programistów. Wyraża się ona np. w nazwach funkcji i zmiennych albo komentarzach. To wszystko sprawia, że patrząc na kod czasem można odnieść wrażenie, że czyta się notatki z lekcji matematyki pisane w języku naturalnym.
Zobaczmy prostą funkcję w Pythonie:
def dodaj(a, b):
"""
Funkcja dodaje dwie liczby.
Argumenty:
a: Pierwsza liczba.
b: Druga liczba.
Zwraca:
Suma a i b.
"""
return a + b
wynik = dodaj(5, 3)
print(wynik) # Oczekiwany wynik: 8
Zakładam, że ta funkcja jest rozumiała dla nie-programisty, co znacznie ułatwiają komentarze (to co znajduje się pomiędzy “”” oraz za #). Komentarze pokazuję bardzo ludzką stronę kodu. Są właściwie osobnym językiem, służącym do komunikacji programisty z innymi programistami.
Well, well, well. CPU ma ma dupie komentarze, podobnie jak inne “ludzkie” aspekty kodu. Nie interesuje go, czy nazwiesz swoją funkcję “add”, “xyz” czy “ItsBritneyBeach”. To wszystko jest lost in translation. Ginie w podczas kompilacji lub interpretacji kodu.
Akcja kompilacja
Oba te procesy, kompilacja i interpretacja, odbywają się poza kontrolą programisty. Są bardzo złożone i wieloetapowe, ale kluczowe dla komunikacji między programistą a maszyną. Co dla nas istotne, ich początkowe etapy to operacje na samym języku. Zalicza się do nich:
- Analiza leksykalna (lexing), podczas której kod napisany przez programistę w języku wysokiego poziomu jest dzielony na tokeny (najmniejsze jednostki znaczące, np. słowa kluczowe, identyfikatory, operatory)
- Analiza składniowa (parsowanie) podczas której sprawdzane jest, czy sekwencja tokenów zgadza się z regułami składni danego języka. Jej efektem jest abstrakcyjne drzewo składniowe (AST), wizualnie przedstawione jako - no właśnie - korzenie drzewa, na przykład takie
- Analiza semantyczna, czyli weryfikacja kodu pod kątem znaczeń. Poprawny składniowo kod może być przecież znaczeniowo i logicznie bez sensu, jak choćby mnożenie stringów. Na tym etapie kompilator sprawdza na przykład, czy operacje i typy danych są zgodne, czy zmienne są deklarowane przed użyciem albo czy liczba argumentów funkcji jest poprawna.
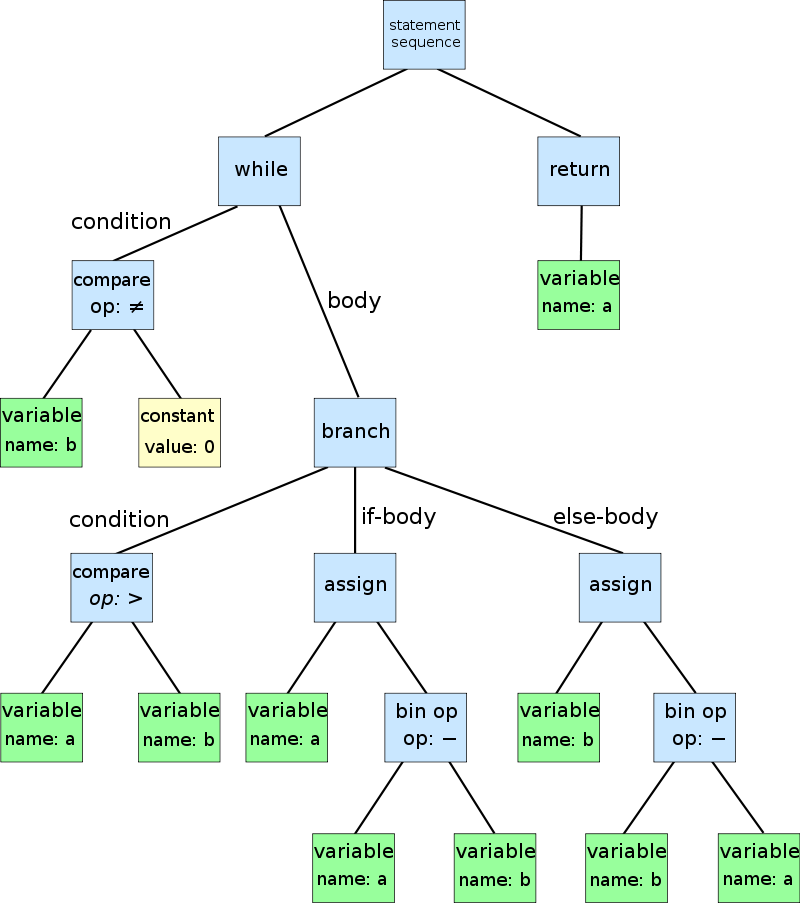{kind=link}
Tak w masakrycznym uproszczeniu wyglądają pierwsze etapy przetwarzania kodu źródłowego w procesie kompilacji lub intepretacji. Świadomie pominę teraz kolejne etapy i przejdę do ich rezultatów.
Efektem kompilacji jest plik wykonywalny lub bytecode dla maszyny wirtualnej danego języka. Dopiero po jego odpaleniu program jest wykonywany. Intepretacja to wykonywanie kodu w locie, więc wszystkie opisane wyżej operacje odbywają się w run timie. Z tego powodu języki kompilowane są w reguły szybsze, chociaż zależy to od wielu czynników - nie są one w tym kontekście istotne.
Obecnie jednak wiele języków programowania dzieli cechy języków intepretowanych i kompilowanych. Java kompilowana jest do bytecodu, który po uruchomieniu programu interpretuje maszyna wirtualna Javy (JVM). Zawarty w niej JIT potrafi zidentyfikować często używane fragmenty bytecodu (aka hotspots) i skompilować je w locie do kodu maszynowego. Z kolei JavaScript teoretycznie jest językiem intepretowanym. Jednak na silniku V8 (używanym na przykład przez Chrome) korzysta z JIT, który w locie kompiluje jej kod źródłowy do natywnego (maszynowego). No magia, bo jak to inaczej nazwać?
Przemówił dziad do obrazu
Jako ludzie mamy wrodzoną skłonność do antropomorfizacji obserwowanych zjawisk. Twierdzimy na przykład, że komputery “rozumieją” wyłącznie język binarny, złożony z samych zer i jedynek. Że mówią do nas w tym języku. Że komunikujemy się z nimi pisząc kod. Bullshit.
Tą powtórką z podstaw kompilacji i interpretacji kodu źrodłowego chciałam podkreślić, że pisanie kodu w języku wysokiego poziomu to nie jest jeszcze komunikacja z maszyną. To nie jest jej “język”, bo ona go nie rozumie.
Komputery - a właściwie procesory, bo na nich się skupiam - wykonują jedynie instrukcje zdefiniowane w ich architekturze. Nie mówią, nie rozumieją, skupione są wyłącznie na pracy. Funkcjonują w ortodoksyjnej kulturze zapierdolu, działając z obłędną prędkością miliardów, a nawet trylionów operacji na sekundę. W pale się nie mieści, jak szybkie są obecnie procesory.
Języki programowania to wygodna warstwa abstrakcji dla nas, ludzi. Pozwalają pisać zrozumiały dla człowieka kod, który w procesie tłumaczenia - kompilacji lub interpretacji (albo obu!) - zostaje przetransformowany w jego inną reprezentację, zrozumiałą przez CPU. Ten dodatkowy etap tłumaczenia kodu napisanego w języku wysokiego poziomu na język zrozumiały przez procesor wykazuje wiele technologicznego kunsztu. Cała ta magia odbywa się w kompilatorach i interpreterach, które wykonują za programistów to niewdzięczne zadanie.
Ponadto podanie procesorowi instrukcji napisanych w “jego języku” z góry zakłada, że dostaniemy od niego odpowiedź w zasadniczno innej formie. Nie oczekujemy od niego komunikatu zwrotnego w tym samym języku, ale w postaci zmaterializowanej w jakimś programie.
Poł żartem: pisać program to trochę jakby mówić do kogoś po angielsku, aby tłumacz (kompilator) przełożył to na język pszczół i dostał odpowiedź w postaci np. aplikacji mobilnej CandyCrush (software).
Dlatego uważam, że języki programowania są nazywane językami trochę na wyrost. Dzielą z językami naturalnymi cechy strukturalne (słownictwo i gramatykę), ale na poziomie komunikacji różnią się zasadniczo. Podsumujmy te różnice:
- języki programowania potrzebują dodatkowej warstwy translacji (kompilacji, interpretacji lub obu), aby być zrozumiałym przez swojego odbiorcę
- komunikacja w języku programowania jest jednostronna: nadawcą jest programista, a odbiorcą procesor, nigdy odwrotnie
- efektem wykonania kodu, “przemówienia” do maszyny, jest jakieś działanie o charakterze niejęzykowym: np. wynik obliczenia, aplikacja, grafika
Języki programowania przypominają bardziej system semaforów albo znaków drogowych: są nośnikiem informacji opartej na symbolach i regułach. W przypadku znaków to istotne dla kierowców informacje o ruchu drogowym. W przypadku np. C to informacja dla kompilatora, jakie operacje ma przetłumaczyć kod natywny. W obu przypadkach komunikacja odbywa się w jedną stronę - od nadawcy, który ustala reguły programu, do CPU, który je wykonuje. Informacja zwrotna w tym procesie to jakiś lepiej lub gorzej działający software.
 Fot. Matt Bango, licencja CC, źródło
Fot. Matt Bango, licencja CC, źródło
Języki programowania jednak niezaprzeczalnie mają wiele punktów przecięcia z językami nautralnymi, ale ten temat rozwinę w kolejnym poście.