Therac-2025
Rozważania o bugach i robieniu rzeczy na odpierdol.
Pomyłki są wpisane w nasze życie. Utwierdza nas w tym nie tylko doświadczenie, ale też przysłowia i mądrości ludowe. „Ten się nie myli, kto nic nie robi”, „mylić się jest rzeczą ludzką”, „tylko głupcy nie mylą się wcale” i tym podobne. Jest to zrozumiałe, bo błędy są po prostu nieodzwonym elementem procesu uczenia się.
Są jednak takie obszary działalności ludzkiej, w której tolerancja na błędy jest niska. Jak wiadomo, saper myli się tylko raz. Chirurg za swoją pomyłkę może iść do więzienia. Sędzia błędną decyzją może zniszczyć komuś życie. Programista natomiast może się mylić do woli, bo bugi są traktowane jako pochodna jego pracy. Nawet jeśli jest to oprogramowanie do sterowania krytycznymi zadaniami elektrowni atomowej albo pocisku balistycznego z głowicą atomową.
 Not bad, not terrible
Not bad, not terrible
Nie twierdzę, że da się zbudować software idealny: pozbawiony bugów, uwzględniający każdy edge case i odporny na cyberataki. Pracujemy na tylu warstwach abstrakcji nadbudowanych nad fizyczną rzeczywistością kąkutera (krzem, atomy, elektrony), że byłoby to pewnie niemożliwe.
Uważam jednak, że:
- wielu bugów czy podatności można by uniknąć, gdyby organizacje miały wdrożone podstawowe procesy QA na każdym etapie SDLC
- błędy w działaniu programów oraz ogólne gównowacenie software’u jest efektem rozpanoszonej i powszechnie akceptowanej niechlujności w branży IT – poczynając od osób piszących kod, przez managerów, testerów, architektów etc.
Myślę, że wszyscy to znamy: kod klepany na kolanie, aby wyrobić się przed releasem. Nic nie wnoszące i robione na odpierdol testy, byleby pokryły wymagany procent kodu. Zlikwidowany dział QA w ramach oszczędności. Mętna dokumentacja, w dodatku nieaktualna. Architektura systemów oderwana od rzeczywistości. Oddawanie developmentu kluczowych komponentów do przypadkowych (byleby tanich!) software house’ów albo agentów AI. Robienie rzeczy na „odwal się”, byleby zamknąć task wyestymowany nieadekwatnie na sesji Scrum pokera i wystawić fakturkę. Rozpanoszony agile, czyli byle jak, bez planu, ale w sprintach. Kultura opacznie zinterpretowanego performance’u – rozumianego jako dowiezienie celu bez weryfikacji jego jakości i długoterminowych konsekwencji.
Chciałabym wierzyć, że nie wszędzie to tak wygląda, ale własne obserwacje i branżowe rozmowy raczej potwierdzają powszechne występowanie takich zjawisk w organizacjach. Akceptacja bylejakości i duża tolerancja dla fuszerki w IT ma jednak realny wpływ na życie każdego z nas. Korzystamy na co dzień z dziesiątek urządzeń, w których działa jakieś oprogramowanie – od telefonu, smartwatcha, przez pralkę i lodówkę, po samochód czy bankomat. Dlatego twierdzę, że konsekwencje dostarczania kiepskiego software’u ponosimy wszyscy.
Pal sześć, że firmy płacą krocie za utrzymywanie niezoptymalizowanych, pozbawionych logiki aplikacji, długu technologicznego i łatanie dziur w systemach. Pal licho, że to naprawienie bugów to często główne zadanie programistów. Co z tego, że jakiś ERP znowu nie działa, raporty się nie generują, a gra się zawiesza. To są naprawdę niegroźne konsekwencje. Nawet jeśli jest to software do podawania wyników testu na chlamydię, to wciąż nie zaliczyłabym tego do poważnych konsekwencji niedopracowanego oprogramowania.
Wyobraźmy sobie jednak, że software robiony na odpierdol i z pominięciem procedur bezpieczeństwa odpowiada za twoje życie, zdrowie lub finanse. Trochę to zmienia perspektywę, a przecież i takie sytuacje się już zdarzały.
Postanowiłam opisać kilka spektakularnych bugów i złych praktyk w tworzeniu oprogramowania ku przestrodze. Pokazują one, co się może stać, kiedy software jest niedostatecznie przemyślany i przetestowany. A materiałów znalazłam tyle, że musiałam rozbić ten wpis na dwa osobne posty. Dużą inspiracją przy doborze tematu była dla mnie książka Matta Parkera przetłumaczona na polski jako „Pi razy oko” (Warszawa 2021), w której autor opisał wiele bugów w softwarze z punktu widzenia matematyka. Serdecznie ją polecam.
HealingKilling software
Zacznę z grubej rury. Oprogramowanie w urządzeniu do radioterapii Therac-25 w latach 80. doprowadziło do śmierci co najmniej 5 osób przez zaaplikowanie im śmiertelnej dawki promieniowania. Sprzęt, który miał leczyć – zabijał.
Producent Therac-25 – firma Atomic Energy of Canada Limited – podjął kilka fatalnych decyzji projektowych przy jego tworzeniu. Po pierwsze, software i hardware urządzenia były testowane w izolacji. Sprzęt w całości był montowany w szpitalach i dopiero tam wykonywano na nim testy integracyjne.
Po drugie, oprogramowanie Therac-25 było napisane w assemblerze PDP-11 i powstało na podstawie kodu legacy z urządzeń Therac-6 i Therac-20. W przeciwieństwie do wcześniejszych wersji, Therac-25 nie miał dodatkowych blokad sprzętowych, więc zabezpieczenia przed np. wprowadzeniem zabójczej dawki promieniowania, były obecne wyłącznie w softwarze. I to była fatalna decyzja w designie, bo opierała się na założeniu, że oprogramowanie jest napisane bezbłędnie i przewiduje wszystkie przypadki brzegowe, co w rzeczywistości raczej się nie zdarza. Therac-25 zawalił właśnie na takim wyjątku.
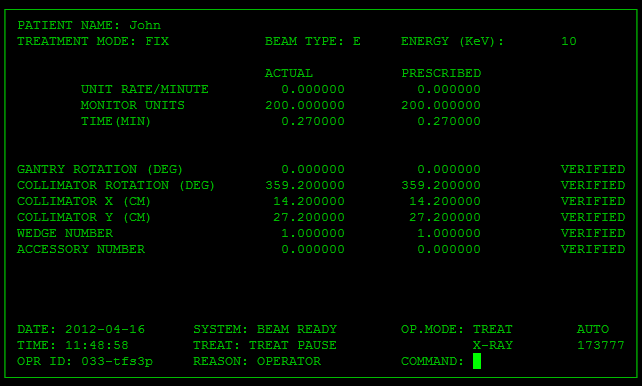 Interfejs graficzny Therac-25
Interfejs graficzny Therac-25
Urządzenie mogło działać w dwóch trybach stosowanych w zależności od celu i metody leczenia:
-
tryb 1 do generowania wiązki elektronów o niskiej energii
-
tryb 2 do generowania wiązki elektronów o wysokiej energii – wymaga on stosowania dodatkowych zabezpieczeń, aby nie uszkodzić zdrowych zdrowych tkanek pacjenta
W Theracu-25 technik manualnie wpisywał polecenia do terminala urządzenia, by przełączać się między trybami radioterapii. Program kolejkował te polecenia we współdzielonym buforze pamięci, a następnie wysyłał instrukcje do hardware’u. Jeśli zwinny technik bardzo szybko wprowadzał polecenia, to dochodziło do klasycznego race condition. Dwa współbieżne procesy (obsługa klawiatury i ustawienie trybu leczenia) korzystały z tego samego zasobu pamięci. Mogło to doprowadzić do sytuacji, że dane na wyświetlaczu były aktualizowane, ale tryb się nie zmieniał. Technik mógł więc widzieć w GUI, że ustawił tryb generowania elektronów w niskiej energii, lecz w backendzie nie doszło do rekonfiguracji. W efekcie takiego scenariusza niektórzy pacjenci zostali potraktowani strumieniem elektronów o dużej energii bez żadnego zabezpieczenia zdrowych taknek, bo – jak wspominałam – w Therac-25 zrezygnowano z dodatkowych blokad sprzętowych. Na marginesie, wprowadzenie mechanizmów wzajemnego wykluczania się (mutexów) mogłoby zapobiec równoczesnym zapisom lub odczytom ustawień krytycznych w urządzeniu.
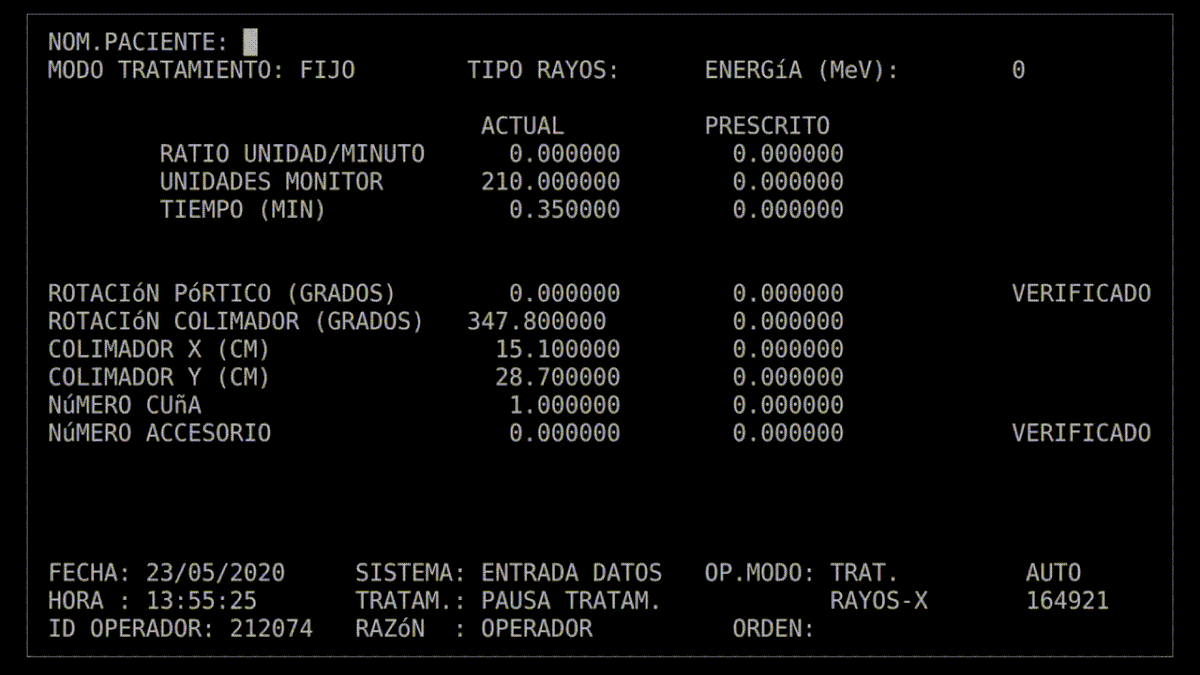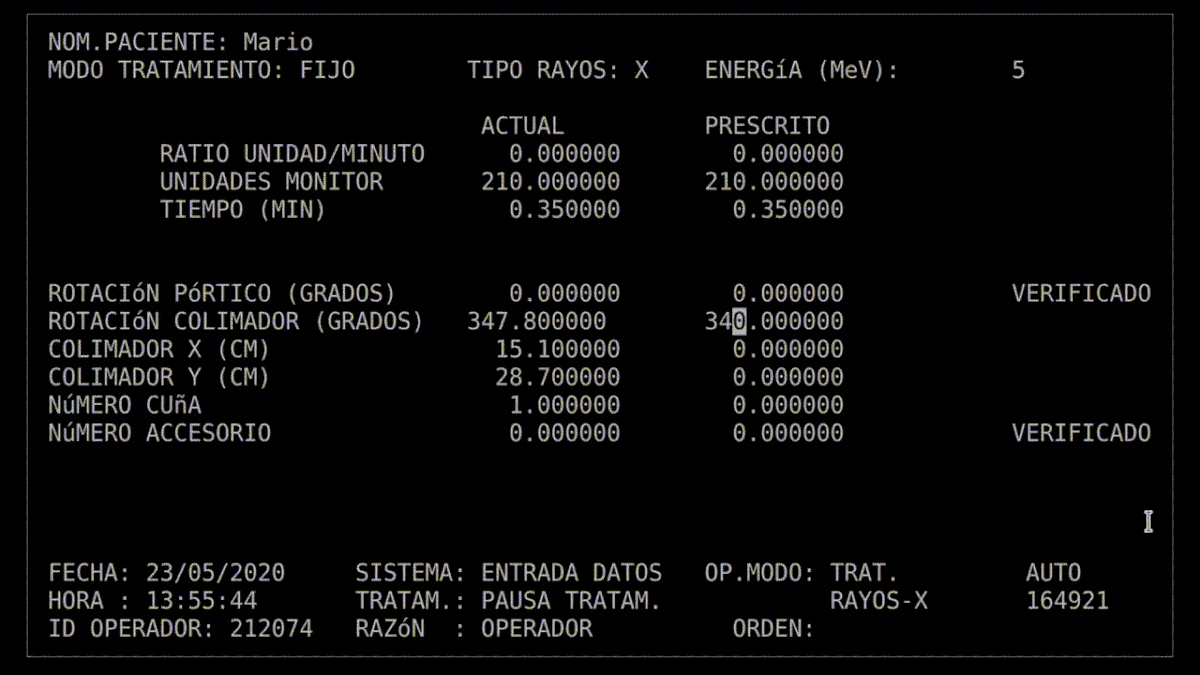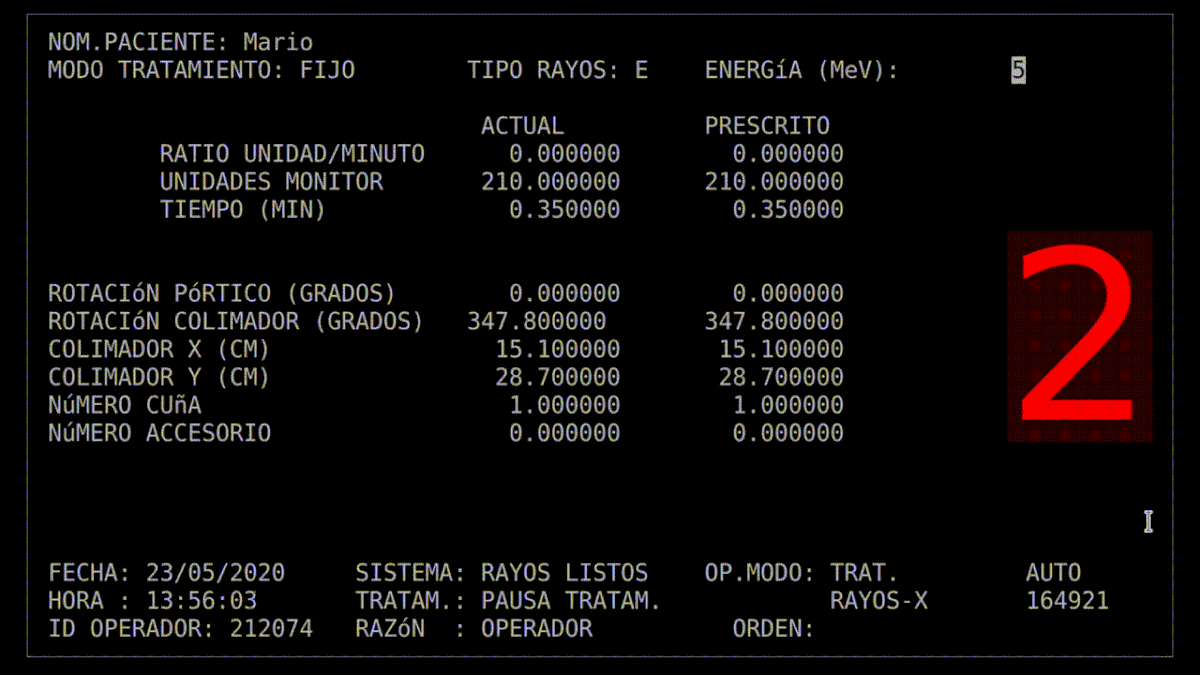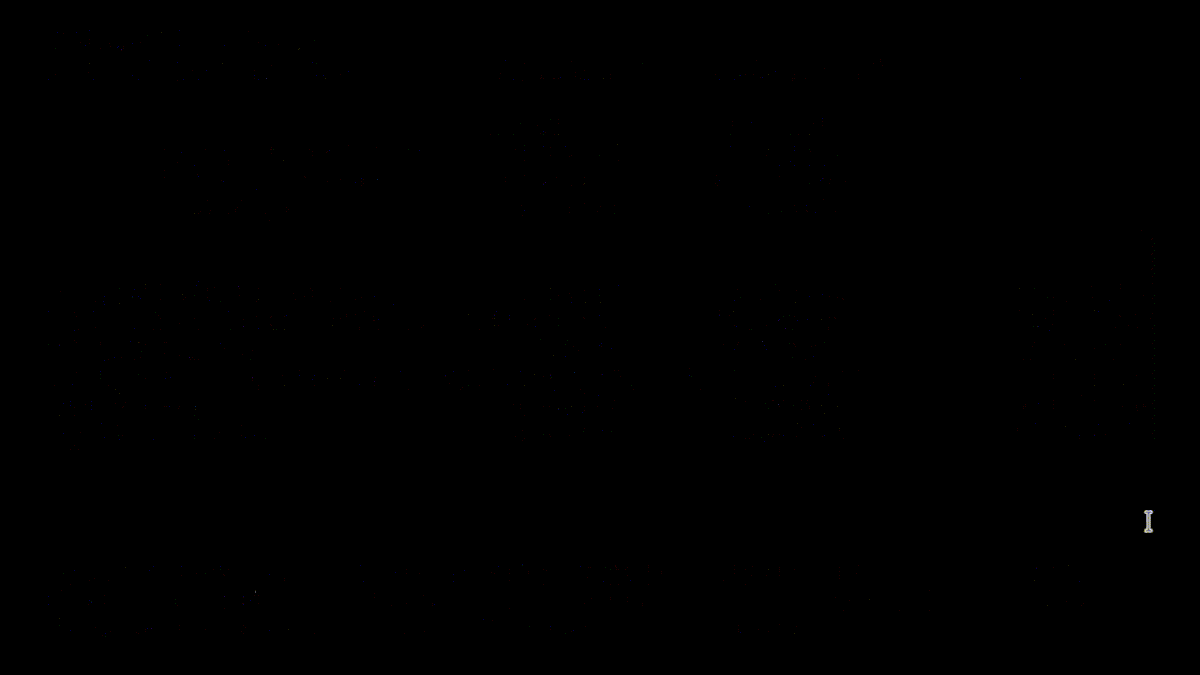 Reprodukcja błędu w oprogramowaniu Therac-25 (kilknij w obraz, by odpalić gifa)
Reprodukcja błędu w oprogramowaniu Therac-25 (kilknij w obraz, by odpalić gifa)
Ponadto instrukcja do Therac-25 była fatalnie napisana. W niektórych komunikatach o błędach wyświetlało się jedynie słowo „MALFUNCTION” (usterka), po którym następowała liczba od 1 do 64. Manual wyjaśniał lakonicznie kody błędów i nie informował, które z nich wskazują na zagrożenie dla życia pacjenta. Technicy nauczyli się więc ignorować nieprecyzyjne sygnały ostrzegawcze. Świetnie całą tą tragiczną historię opisuje film na kanale Low Level.
Jeśli myślicie, że Therac-25 to pieśń przeszłości to nic bardziej mylnego.
Bardzo podobny przypadek wydarzył się w Narodowym Instytucie Onkologicznym w Panama City w 2001 roku. 28 pacjentów dostało zawyżoną dawkę promieniowania z aparatu do radioterapii RTP/2 od amerykańskiej firmy Multidata Systems International. W tym przypadku deploy na produkcję niezbyt przemyślanego fixa.
Operatorzy RTP/2 byli zobowiązani do manualnego wpisywania informacji o liczbie tzw. bloków ochronnych – osłon, które w radioterapii stosuje się, aby zmniejszyć dawkę promieniowania dla zdrowych tkanek i narządów. Późniejsze śledztwo wykazało, że software umożliwiał technikom wprowadzenie nieprawidłowych i niebezpiecznych dla życia pacjentów wartości. System początkowo dopuszczał wpisanie maksymalnie czterech bloków do jednego pola, jednak na prośbę operatorów producent zwiększył ten limit do pięciu. Niestety reguły walidacji wprowadzanych danych się wtedy posypały. System umożliwił wprowadzanie całkowitej liczby bloków ochronnych do jednego pola – w taki sposób, jakby stanowiły jeden niepodzielny moduł. Zaburzało to obliczenie wartości innych parametrów, w tym czasu naświetlania. W efekcie pacjenci byli naświetlani dłużej niż powinni przy niedostatecznej liczbie bloków ochronnych.
Brak mechanizmów kontroli poprawności danych wejściowych (walidacja!) doprowadził do śmieci 8 pacjentów i spowodował poważne problemy zdrowotne u kolejne 20 osób. Technicy obsługujący urządzenie zostali oskarżeni przez rodziny pacjentów o morderstwo. Nie udało mi się dotrzeć do żadnych informacji, jakie były ich dalsze losy.
Jako w niebie
Chyba obecnie w większości samolotów pasażerskich działa system fly-by-wire. Termin ten w dużym skrócie oznacza sposób sterowania samolotem, który trochę przypomina grę typu symulator lotu. Pilot macha w niej drążkiem trochę na niby – bo nie jest on w żaden sposób połączony mechanicznie z powierzchniami sterowymi samolotu. Ruchy pilota są przekazywane do komputera pokładowego, w którym dzieje się cała magia: przetwarzanie sygnałów z drążka, ich modyfikacja, aby jak najlepiej dostosować je do parametrów lotu i przesłanie ich po kablu do siłowników, np. w lotkach. Niezawodny software jest w systemie fly-by-wire podstawą bezpieczeństwa pasażerów.
Model Boeinga 737 MAX nie miał pełnego fly-by-wire (był on zastosowany jedynie do sterowania spojlerami), ale za to korzystał z innych systemów wspomagających pracę pilotów. Zalicza się do nich MCAS (skrót od: Maneuvering Characteristics Augmentation System). System ten miał przeciwdziałać przeciągnięciom, czyli gwałtownym spadkom siły nośnej i utraty sterowności samolotu. Był zaprogramowany w taki sposób, że analizował dane z sensora i w przypadku wykrycia przeciągnięcia, wymuszał ostrą korektę kursu: ustawiał samolot w pozycji nose-down (przód jest pochylony i znajduje się niżej względem ogona) i jednocześnie uniemożliwiał pilotom przejęcie kontroli nad sterem. Użyłam słowa „sensor” w liczbie pojedynczej bardzo świadomie. Tak, po wdrożonych zmianach w stosunku do inicjalnego projektu MCAS zbierał dane tylko z jednego czujnika. Oznacza to, że przy awarii czujnika oprogramowanie wymuszało nieprawidłowe manewry samolotu i utratę sterowności, której – w założeniu – miało przeciwdziałać. Ten skandaliczny i w zasadzie niczym nieuzasadniony brak redundancji i zasady fail-safe spowodował 2 katastrofy lotnicze, w wyniku których życie straciło 346 osób.
Na marginesie można dodać, że Boeingi 787 Dreamliner (mamy je we flocie LOT-u) też miał buga w oprogramowaniu. Jeśli maszyna chodziła dłużej niż 248 dni bez resetu, to jej firmware powodował totalne odcięcie zasilania w maszynie – teoretycznie mogło do tego dojść nawet w trakcie lotu. Internetowe CSI z Reddita doszło do wniosku, że krytyczna liczba 248 dni ładnie tłumaczy się na potencjalne przekręcenie się licznika dla dodatnich signed integers w liczbie 32-bitowej. Maksymalna wartość jaką może ona mieć to: 2³¹ – 1 = 2 147 483 647. Jeśli założymy, że jest to liczba centysekund (0,01 sekundy), podczas których nie doszło do resetu oprogramowania Dreamlinera, to otrzymamy takie równanie:
[2 147 483 647 (maks. liczba 32-bitowa) * 0,01 (centysekunda) ] / 60 (liczba sekund w minucie) × 60 (liczba minut w godzinie) × 24 (dni) ≈ 248,5 dnia.
Mnie to przekonuje, tym bardziej, że niektóre systemy używają centysekund do liczenia czasu. Tak robił na przykład software w Apollo Guidance Computer.
Historia Boeingów jest dobrym segwayem do kolejnego rozdziału. Amerykański koncern pokusił się bowiem także o podbój kosmosu. Zgadnijcie, jak im to wyszło…
Boeing Starliner powstał w ramach programu Commercial Crew Program finansowanego przez NASA – jego celem było zastąpienie ruskich Sojuzów w przelotach na Międzynarodową Stację Kosmiczną (ISS). Celem wizerunkowym było zrobienie amerykańskiej astronautyki „great again” po rezygnacji z programu wahadłowców kosmicznych w 2011 roku.
Podczas bezzałogowego lotu testowego bug w oprogramowaniu Starlinera spowodował opóźnienie wewnętrznego zegara o 11 godzin (!!!). Z powodu tak dużego opóźnienia pojazd w nieodpowiednim czasie uruchomił silniki i zużył tak dużo paliwa, że nie miał już na czym dolecieć do ISS. Podczas testu odkryto także inne bugi w oprogramowaniu.
Przygotowania do lotu załogowego Starlinera ciągnęły się jak smród po gaciach, bo za każdym razem wychodziły kolejne usterki sprzętu lub oprogramowania. Kiedy wreszcie udało się Boeingowi wysłać astronautów na stację kosmiczną, to nie udało się mu sprowadzić ich z powrotem – z powodu stwierdzonego wycieku helu i awarii silników NASA uznała to za zbyt niebezpieczne. Pozwoliło to Elonowi Muskowi zbić kapitał polityczny, bo astronautów na ziemię sprowadził jego SpaceX Dragon. Sunita Williams i Butch Wilmore spędzili na kosmicznej delegacji 286 dni zamiast planowanych 8.
A wy narzekacie na swoje nadgodziny.
Tak i w kosmosie
Jeden z najbardziej inspirujących językoznawców, Ferdinand de Saussure, stwierdził, że język to system różnic. Znaczenie danego znaku językowego można określić jedynie w kontekście tego, jakimi cechami różni się on od innych znaków systemu językowego. Użytkownicy języków naturalnych nie muszą się nad tym zastanawiać, bo intuicyjnie rozumieją różnicę między słowem “kot” i “kod”. Jeśli się przejęzyczą albo pomylą jedno z drugim, to zapewne szybko się sami poprawią albo zrobi to ich współrozmówca, o ile włada tym samym językiem.
Komputery są bardziej dosłowne. To, co napisze programista, jest interpretowane wedle litery prawa. Dlatego właśnie pisanie kodu to nietrywialna sztuka, która wymaga precyzyjnego używania symboli i składni danego języka. Tu nie ma miejsca na dowolność. Symbole różnią się od siebie – surprise, surprise – i postawienie choćby przecinka z złym miejscu może spowodować crash całego programu. A teraz historia o tym, jak drobna literówka wysłała rakietę w przestworza. Oh, wait, właściwie to do piachu.
Działo się to w latach 60., w czasie intensywnej eksploracji kosmosu i triumfu programów Apollo i Mariner. W pale się nie mieści, że w tych czasach nie było jeszcze terminali czy GUI do pisania kodu. Programy do rakiet i systemów do nawigacji były pisane odręcznie na tzw. coding sheets, a następnie przepisywane na maszynie do robienia dziurek (eng. keypunch) na karty perforowane, które następnie były odczytywane przez komputer. Podczas takiej transkrypcji w kodzie Marinera 1 – sondzie, którą NASA chciała wysłać w okolice Wenus – znalazła się z pozoru błaha literówka. Zabrakło poziomej kreski (eng. overbar) nad jednym z wyrażeń matematycznych. Skutkowało to tym, że statek otrzymywał polecenia nawigacyjne na podstawie błędnych równań. Kreska służyła do uśredniania wartości w czasie. Jej brak powodował, że nic nieznaczące, minimalne zaburzenia w odczytach czujników były traktowane przez program jako poważne nieprawidłowości w parametrach lotu, wymagające natychmiastowej korekty kursu. W efekcie rakieta zaczęła miotać się kuna w agreście i oficer range safety musiał wydać jej sygnał do samozniszczenia parę minut po starcie, aby nie uderzyła w tereny zamieszkane. Do pieca poszło ponad 18 milionów ówczesnych dolarów.
Do programistów nie miała też szczęścia rakieta Ariane 5, którą Europejska Agencja Kosmiczna zbudowała w celu wynoszenia satelitów i innych ładunków na orbitę okołoziemską. W jej oprogramowaniu sporo było martwego kodu z poprzedniej wersji rakiety (Ariane 4), który nie był dobrze zabezpieczony przed integer overflow, do którego doszło podczas feralnego lotu. Nieprawidłowa obsługa wyjątku spowodowała utratę kontroli nad rakietą, która eksplodowała 37 sekund po starcie. Śpij słodko, Arianko [*]. Na szczęście w kolejnych wersjach rakiety bug został naprawiony i Ariane 5 latały jak oczadziałe, wynosząc na orbitę głównie satelity telekomunikacyjne.
Ale jeszcze lepszy przypadek to historia Mars Climate Orbitera. Była to sonda kosmiczna od NASA, która miała badać Marsa, ale zjarała się zanim do niego doleciała. Śledztwo wykazało, że oprogramowanie Orbitera miało wielkiego jak zmutowany karaczan buga. Polegał on na tym, że software nawigacyjny dostarczony przez prywatne przedsiębiorstwo Lockheed Martin rejestrował dane wyrażone w jednostkach imperialnych (sekundach funta-siły). Odbierający je moduł nawigacyjny od NASA oczekiwał danych w jednostkach metrycznych (niutonosekundach). Program nie konwertował jednostek, więc chyba w kategoriach cudu można rozpatrywać to, że sonda w ogóle doleciała do Marsa. A dokładniej do górnych warstw jego atmosfery, w której się spaliła – z powodu opisanego wyżej błędu nie zdążyła odpowiednio dostosować trajektorii lotu i wyhamować przed wejściem w atmosferę. Ten przykład pokazuje, że testy integracyjne to nie jest fanaberia nawiedzonych programistów, tylko realna potrzeba, niezbędna do tego, by zagwarantować poprawne działanie oprogramowania.
A na koniec mój ulubiony przykład, całkiem niedawny, bo z 2019 roku. Nie wiem, czy wiecie, ale Izrael ma swój wkład w podbój kosmosu, a dokładniej – Księżyca. Lądownik Beresheet miał na Srebrnym Globie prowadzić badania i przy okazji zostawić tam kilka dość osobliwych parafernaliów: kopię angielskojęzycznej Wikipedii, Torę, flagę Izraela, pamiętniki ocalonych z Holocaustu oraz – trochę tu niepasujące – próbki genetyczne niesporczaków zatopione w żywicy epoksydowej. Nie zdążył.
Podczas podejścia do lądowania uległ awarii jeden z żyroskopów. Obsługa naziemna zdecydowała się jego manualny reset. Niestety operacja miała nieprzewidziane konsekwencje, bo software Beresheet nie miał izolacji błędów – reset żyroskopu zresetował również główny moduł nawigacyjny, odpowiedzialny m.in. za pracę silnika. Przy lądowaniu pełni on kluczową rolę, bo pojazdy kosmiczne używają go do wytracania prędkości (w kosmonautyce nazywa się to power descent). Manualny reset w kluczowym momencie wyłączył więc silnik Beresheet, który mknął jak kosmiczny bolid. Ostatni odczyt telemetryczny wskazał, że na wysokości 150 m nad powierzchnią Księżyca nadal leciał z prędkością ponad 500 km/h.
Jak nietrudno się domyślić, lądownik roztrzaskał się o powierzchnię Księżyca razem z całym majdanem, z którym leciał. Zdążył sobie pstryknąć przedśmiertne selfie, które możecie zobaczyć tutaj.
Na tej historii kończę pierwszą część posta. CDN.